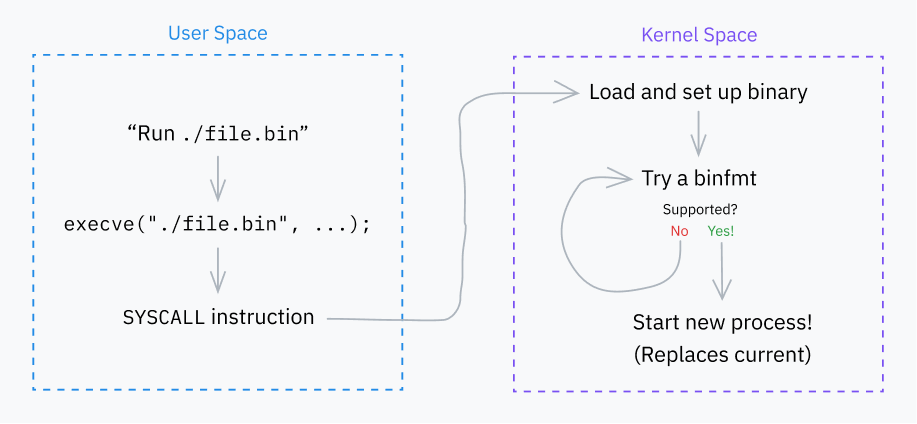
So far, we’ve covered how CPUs execute machine code loaded from executables, what ring-based security is, and how syscalls work. In this section, we’ll dive deep into the Linux kernel to figure out how programs are loaded and run in the first place.
We’re specifically going to look at Linux on x86-64. Why?
Linux is a fully featured production OS for desktop, mobile, and server use cases. Linux is open source, so it’s super easy to research just by reading its source code. I will be directly referencing some kernel code in this article!
x86-64 is the architecture that most modern desktop computers use, and the target architecture of a lot of code. The subset of behavior I mention that is x86-64-specific will generalize well.
Most of what we learn will generalize well to other operating systems and architectures, even if they differ in various specific ways.
Basic Behavior of Exec Syscalls
Let’s start with a very important system call: execve. It loads a program and, if successful, replaces the current process with that program. A couple other syscalls (execlp, execvpe, etc.) exist, but they all layer on top of execve in various fashions.
Aside: execveat
execve is actually built on top of execveat, a more general syscall that runs a program with some configuration options. For simplicity, we’ll mostly talk about execve; the only difference is that it provides some defaults to execveat.
Curious what ve stands for? The v means one parameter is the vector (list) of arguments (argv), and the e means another parameter is the vector of environment variables (envp). Various other exec syscalls have different suffixes to designate different call signatures. The at in execveat is just “at”, because it specifies the location to run execve at.
The filename argument specifies a path to the program to run.
argv is a null-terminated (meaning the last item is a null pointer) list of arguments to the program. The argc argument you’ll commonly see passed to C main functions is actually calculated later by the syscall, thus the null-termination.
The envp argument contains another null-terminated list of environment variables used as context for the application. They’re… conventionally KEY=VALUE pairs. Conventionally. I love computers.
Fun fact! You know that convention where a program’s first argument is the name of the program? That’s purely a convention, and isn’t actually set by the execve syscall itself! The first argument will be whatever is passed to execve as the first item in the argv argument, even if it has nothing to do with the program name.
Interestingly, execve does have some code that assumes argv[0] is the program name. More on this later when we talk about interpreted scripting languages.
Step 0: Definition
We already know how syscalls work, but we’ve never seen a real-world code example! Let’s look at the Linux kernel’s source code to see how execve is defined under the hood:
SYSCALL_DEFINE3 is a macro for defining a 3-argument system call’s code.
I was curious why the arity is hardcoded in the macro name; I googled around and learned that this was a workaround to fix some security vulnerability.
The filename argument is passed to a getname() function, which copies the string from user space to kernel space and does some usage tracking things. It returns a filename struct, which is defined in include/linux/fs.h. It stores a pointer to the original string in user space as well as a new pointer to the value copied to kernel space:
struct filename {constchar*name; /* pointer to actual string */const __user char*uptr; /* original userland pointer */int refcnt;struct audit_names *aname;constchar iname[];};
The execve system call then calls a do_execve() function. This, in turn, calls do_execveat_common()with some defaults. The execveat syscall which I mentioned earlier also calls do_execveat_common(), but passes through more user-provided options.
In the below snippet, I’ve included the definitions of both do_execve and do_execveat:
In execveat, a file descriptor (a type of id that points to some resource) is passed to the syscall and then to do_execveat_common. This specifies the directory to execute the program relative to.
In execve, a special value is used for the file descriptor argument, AT_FDCWD. This is a shared constant in the Linux kernel that tells functions to interpret pathnames as relative to the current working directory. Functions that accept file descriptors usually include a manual check like if (fd == AT_FDCWD) { /* special codepath */ }.
Step 1: Setup
We’ve now reached do_execveat_common, the core function handling program execution. We’re going to take a brief step back from staring at code to get a bigger picture view of what this function does.
The first major job of do_execveat_common is setting up a struct called linux_binprm. I won’t include a copy of the whole struct definition, but there are several important fields to go over:
Data structures like mm_struct and vm_area_struct are defined to prepare virtual memory management for the new program.
argc and envc are calculated and stored to be passed to the program.
filename and interp store the filename of the program and its interpreter, respectively. These start out equal to each other, but can change in some cases: one such case is when running interpreted scripts with a shebang. When executing a Python program, for example, filename points to the source file but interp is the path to the Python interpreter.
buf is an array filled with the first 256 bytes of the file to be executed. It’s used to detect the format of the file and load script shebangs.
As we can see, its length is defined as the constant BINPRM_BUF_SIZE. By searching the codebase for this string, we can find a definition for this in include/uapi/linux/binfmts.h:
So, the kernel loads the opening 256 bytes of the executed file into this memory buffer.
Aside: what’s a UAPI?
You might notice that the above code’s path contains /uapi/. Why isn’t the length defined in the same file as the linux_binprm struct, include/linux/binfmts.h?
UAPI stands for “userspace API.” In this case, it means someone decided that the length of the buffer should be part of the kernel’s public API. In theory, everything UAPI is exposed to userland, and everything non-UAPI is private to kernel code.
Kernel and user space code originally coexisted in one jumbled mass. In 2012, UAPI code was refactored into a separate directory as an attempt to improve maintainability.
Step 2: Binfmts
The kernel’s next major job is iterating through a bunch of “binfmt” (binary format) handlers. These handlers are defined in files like fs/binfmt_elf.c and fs/binfmt_flat.c. Kernel modules can also add their own binfmt handlers to the pool.
Each handler exposes a load_binary() function which takes a linux_binprm struct and checks if the handler understands the program’s format.
This often involves looking for magic numbers in the buffer, attempting to decode the start of the program (also from the buffer), and/or checking the file extension. If the handler does support the format, it prepares the program for execution and returns a success code. Otherwise, it quits early and returns an error code.
The kernel tries the load_binary() function of each binfmt until it reaches one that succeeds. Sometimes these will run recursively; for example, if a script has an interpreter specified and that interpreter is, itself, a script, the hierarchy might be binfmt_script > binfmt_script > binfmt_elf (where ELF is the executable format at the end of the chain).
Format Highlight: Scripts
Of the many formats Linux supports, binfmt_script is the first I want to specifically talk about.
Have you ever read or written a shebang? That line at the start of some scripts that specifies the path to the interpreter?
1
#!/bin/bash
I always just assumed these were handled by the shell, but no! Shebangs are actually a feature of the kernel, and scripts are executed with the same syscalls as every other program. Computers are so cool.
Take a look at how fs/binfmt_script.c checks if a file starts with a shebang:
/* Not ours to exec if we don't start with "#!". */if ((bprm->buf[0] !='#') || (bprm->buf[1] !='!'))return-ENOEXEC;
If the file does start with a shebang, the binfmt handler then reads the interpreter path and any space-separated arguments after the path. It stops when it hits either a newline or the end of the buffer.
There are two interesting, wonky things going on here.
First of all, remember that buffer in linux_binprm that was filled with the first 256 bytes of the file? That’s used for executable format detection, but that same buffer is also what shebangs are read out of in binfmt_script.
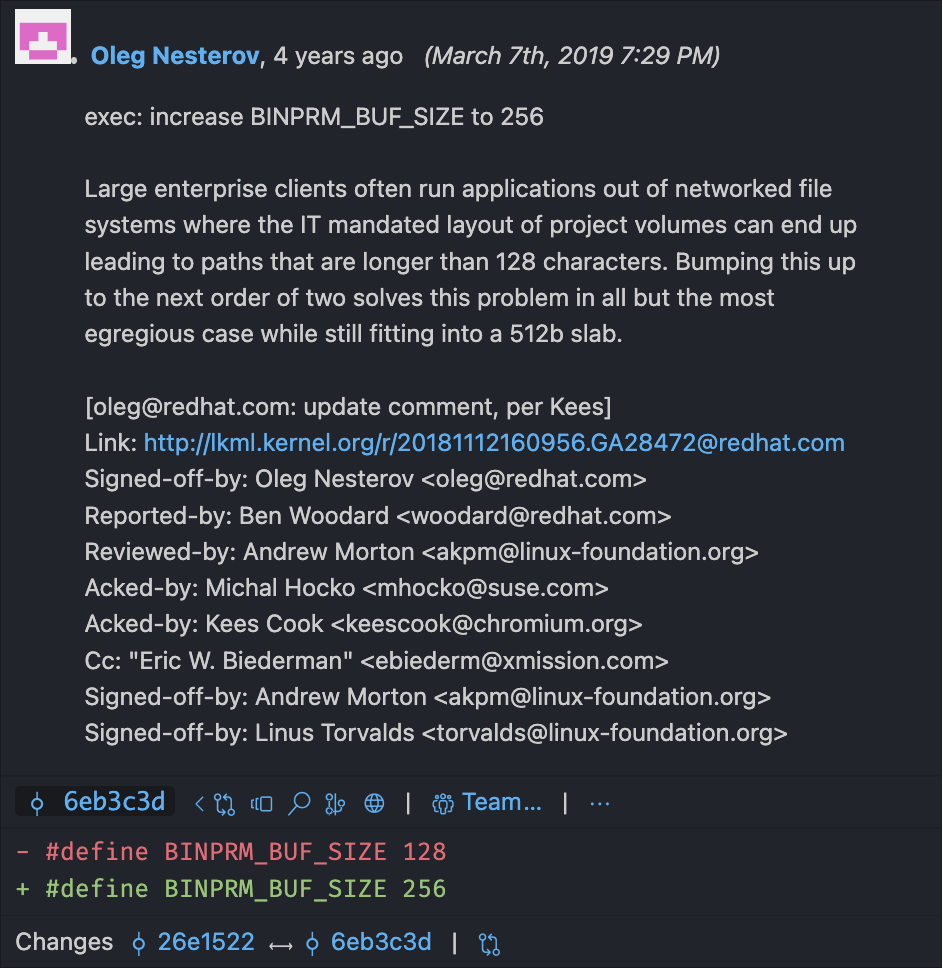
During my research, I read an article that described the buffer as 128 bytes long. At some point after that article was published, the length was doubled to 256 bytes! Curious why, I checked the Git blame — a log of everybody who edited a certain line of code — for the line where BINPRM_BUF_SIZE is defined in the Linux source code. Lo and behold…
COMPUTERS ARE SO COOL!
Since shebangs are handled by the kernel, and pull from buf instead of loading the whole file, they’re always truncated to the length of buf. Apparently, 4 years ago, someone got annoyed by the kernel truncating their >128-character paths, and their solution was to double the truncation point by doubling the buffer size! Today, on your very own Linux machine, if you have a shebang line more than 256 characters long, everything past 256 characters will be completely lost.
Imagine having a bug because of this. Imagine trying to figure out the root cause of what’s breaking your code. Imagine how it would feel, discovering that the problem is deep within the Linux kernel. Woe to the next IT person at a massive enterprise who discovers that part of a path has mysteriously gone missing.
The second wonky thing: remember how it’s only convention for argv[0] to be the program name, how the caller can pass any argv they want to an exec syscall and it will pass through unmoderated?
It just so happens that binfmt_script is one of those places that assumesargv[0] is the program name. It always removes argv[0], and then adds the following to the start of argv:
After updating argv, the handler finishes preparing the file for execution by setting linux_binprm.interp to the interpreter path (in this case, the Node binary). Finally, it returns 0 to indicate success preparing the program for execution.
Format Highlight: Miscellaneous Interpreters
Another interesting handler is binfmt_misc. It opens up the ability to add some limited formats through userland configuration, by mounting a special file system at /proc/sys/fs/binfmt_misc/. Programs can perform specially formatted writes to files in this directory to add their own handlers. Each configuration entry specifies:
How to detect their file format. This can specify either a magic number at a certain offset or a file extension to look for.
The path to an interpreter executable. There’s no way to specify interpreter arguments, so a wrapper script is needed if those are desired.
Some configuration flags, including one specifying how binfmt_misc updates argv.
This binfmt_misc system is often used by Java installations, configured to detect class files by their 0xCAFEBABE magic bytes and JAR files by their extension. On my particular system, a handler is configured that detects Python bytecode by its .pyc extension and passes it to the appropriate handler.
This is a pretty cool way to let program installers add support for their own formats without needing to write highly privileged kernel code.
In the End (Not the Linkin Park Song)
An exec syscall will always end up in one of two paths:
It will eventually reach an executable binary format that it understands, perhaps after several layers of script interpreters, and run that code. At this point, the old code has been replaced.
… or it will exhaust all its options and return an error code to the calling program, tail between its legs.
If you’ve ever used a Unix-like system, you might’ve noticed that shell scripts run from a terminal still execute if they don’t have a shebang line or .sh extension. You can test this out right now if you have a non-Windows terminal handy:
(chmod +x tells the OS that a file is an executable. You won’t be able to run it otherwise.)
So, why does the shell script run as a shell script? The kernel’s format handlers should have no clear way of detecting shell scripts without any discernible label!
Well, it turns out that this behavior isn’t part of the kernel. It’s actually a common way for your shell to handle a failure case.
When you execute a file using a shell and the exec syscall fails, most shells will retry executing the file as a shell script by executing a shell with the filename as the first argument. Bash will typically use itself as the interpreter, while ZSH uses whatever sh is, usually Bourne shell.
This behavior is so common because it’s specified in POSIX, an old standard designed to make code portable between Unix systems. While POSIX isn’t strictly followed by most tools or operating systems, many of its conventions are still shared.
If [an exec syscall] fails due to an error equivalent to the [ENOEXEC] error, the shell shall execute a command equivalent to having a shell invoked with the command name as its first operand, with any remaining arguments passed to the new shell. If the executable file is not a text file, the shell may bypass this command execution. In this case, it shall write an error message and shall return an exit status of 126.